多级分流
随着智能设备的出现,我们正式进入了大数据时代。是个App,都不断的在收集个人的行为与数据。同时,智能设备的出现,使人们的行为发生了很大的变化,大量的线下服务走到线上,比如外卖、叫车、购物等。这么多的数据传输,使我们经常听到一个网站或者服务的QPS有多少多少。比如阿里云公布的2020年双11订单创建峰值是58.3万笔/秒。显然,一台服务器是承受不了同时这么多的访问的。我们就能想到使用多台服务器来同时提供服务。
作为一个后端开发,我们知道,一个支撑几万用户的系统架构与一个支撑上千万用户的架构,在成本上来说,完全不是一个量级的。架构变得复杂之后,缓存、队列、网关、监控等非业务功能性的东西,成本也会变得很可观。
自然,我们可以想到,如果请求可以尽可能少到达后端,那么后端的成本及复杂度可以大大的减少。成本与稳定性可以达到更有效的保证。
以秒杀为例,几百万的人同时在抢几百瓶的茅台,理论上流入到后端有效的流量可能只有几百。当然,我们不会控制的这么精确。
后端流量是如此的,前端也是如此。一个请求从发出到得到响应中间要经过好几层,如果我们可以把流量在不同的级别中进行分流,那么,我们的总体成本将大大的减少。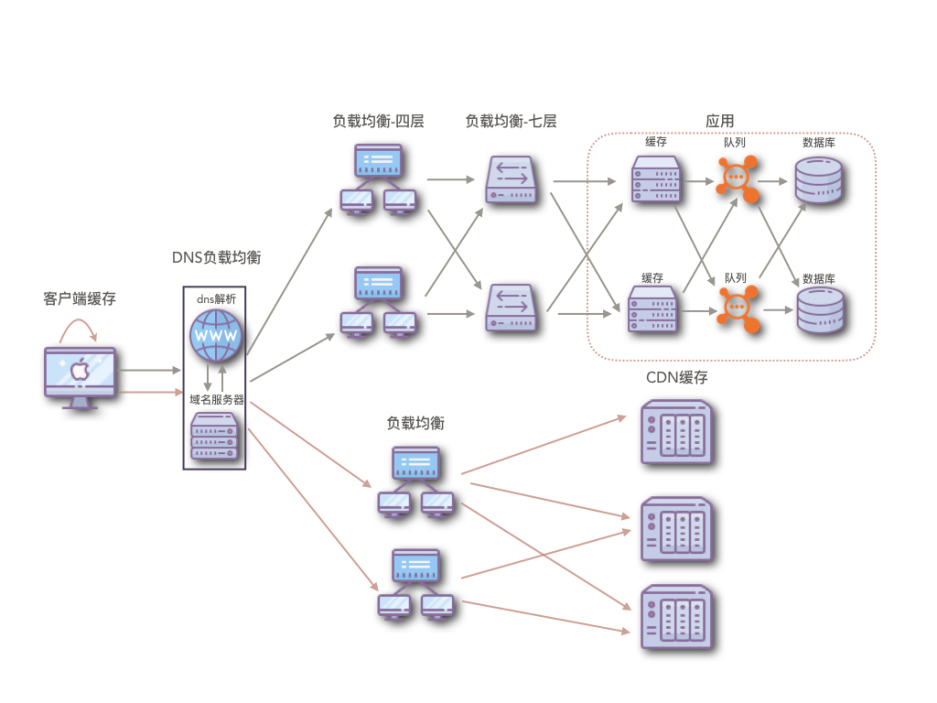
要知道流量怎么进行分级分流,我们就得知道一个请求的从发出到得到响应,都经历了哪些。通常的当我们在浏览器中输入 www.3world.top 时,需要DNS来帮助我们来做域名解析,我们来看域名解析这一步,能帮我们怎么分流。
DNS(域名解析)分流
我们开发中经常配置Host,比如我们需要把 www.3world.top 映射到本地启动的服务器,那么需要添加一条Host记录
1 | |
这就让我们想象中的DNS是一本厚厚的字典,心想DNS服务要应付那么大的查询流量,还在从这么多的数据中查询出来ip地址,不容易啊。
但实际上世界根域名服务器的ZONE文件只有2MB大小,打印都能打印的出来,这就得我们不得不惊叹其巧妙的设计了。
DNS域名空间结构
整个互联网的域名空间结构为树结构。我们知道树结构通常来说叶子节点才是数据的主要存储点,非叶子节点主要起索引作用。这里主要有一个树高与节点大小的平衡问题。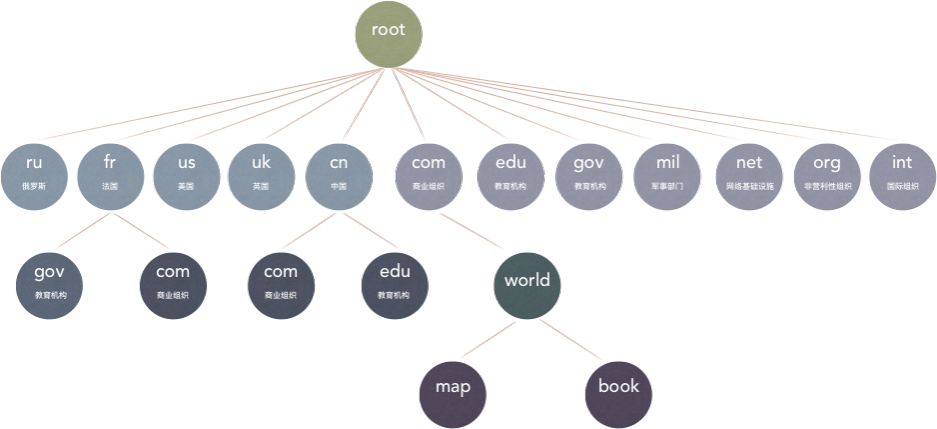
DNS域名空间结构的根节点为根DNS服务器,在整个Internet上有13组根服务器,注意,这里是13组,不是13台。
顶级域名
根DNS服务器往下的第一级节点称为顶级域名。顶级域名最早的时候分为通用顶级域名(gTLD)和国家地区代码顶级域名(ccTLD)。在http://www.iana.org/domains/root/db中可以看到所有的顶级域名。
通用顶级域名
通用顶级域名主要有以下几种
- .com 商业组织
- .edu 教育机构
- .gov 政府部门
- .mil 军事部门
- .net 网络基础设施
- .org 非营利性组织
- .int 国际组织
国家地区代码顶级域名
国家地区代码顶级域名一般取两位国家码,比如中国的cn,香港的hk,美国的us等。新通用顶级域名
互联网名称与数字地址分配机构(ICANN)曾于2011年6月的新加坡会议上通过增设新通用顶级域名(New gTLD)的决议,并首次批准通用顶级域名可以使用多种语言字符表示。任何机构和个人都有权在2012年1月至5月向ICANN提交新通用顶级域名的申请。这就诞生了很多新的顶级域名。
权威域名服务器
顶级域名的往下一个节点都是一个子域,比如3world.top是顶级域top的子域,taobao.com是顶级域com的子域。子域的服务器叫权威域名服务器。每个权威域名服务器可以及一个或者多个区域进行解析。权威域名服务器可以再往下分拆,拆成更细粒度的权威域服务器。直至叶子节点,得到IP地址。DNS解析过程

当我们在浏览器中输入 www.3world.top 客户端会先检查本地的DNS缓存。
本地DNS收到查询请求后,会按照“是否有 www.3world.top 的权威服务器”→“是否有3world.top的权威服务器”→“是否有top的权威服务器”的顺序,依次查询自己的地址记录,如果都没有查询到,就会一直找到最后点号代表的根域名服务器为止。
现在假设本地DNS是全新的,上面不存在任何域名的权威服务器记录,所以当DNS查询请求一直查到根域名服务器之后,它将会得到“top的权威服务器”的地址记录,然后通过“top的权威服务器”,得到“3world.top的权威服务器”的地址记录,以此类推,最后找到能够解释 “www.3world.top” 的权威服务器地址。
查询到DNS缓存之后,会缓存到本地DNS中。win7 ~ 11 的系统,默认 Windows DNS 缓存是 86400 秒(24小时)。
通过上面所述我们了解了域名怎么得到服务器地址,那怎么通过域名解析到进行分流呢。我们能想到最简单的方法
1.一个域名解析服务返回多个IP,客户端根据算法选择
2.域名解析是个服务器,可以均衡的返回不同的服务器地址。
DNS解析记录类型
我们先说一下DNS常用的解析记录类型都有哪些。
A记录
A(Address)记录是用来指定主机名(或域名)对应的IP地址记录。
CNAME记录
通常称别名解析,是主机名到主机名的映射。当需要将域名指向另一个域名,再由另一个域名提供 IP 地址,就需要添加 CNAME 记录,最常用到 CNAME的场景包括做CDN、企业邮箱、全局流量管理等。
NS记录
如果需要把子域名交给其他DNS服务商解析,就需要添加NS记录(Name Server)。NS记录是域名服务器记录,用来指定该域名由哪个DNS服务器来进行解析。NS记录中的IP即为该DNS服务器的IP地址。大多数域名注册商默认用自己的NS服务器来解析用户的DNS记录。DNS服务器NS记录地址一般以以下的形式出现:ns1.domain.com、ns2.domain.com等。
MX记录
MX(Mail Exchanger)记录是邮件交换记录,主要用于邮箱解析,在邮件系统发送邮件时根据收信人的地址后缀进行邮件服务器的定位。MX记录允许设置一个优先级,当多个邮件服务器可用时,会根据该值决定投递邮件的服务器。
MX记录的权重对 Mail 服务非常重要,当发送邮件时,Mail 服务器先对域名进行解析,查找 MX记录。先找权重数最小的服务器(比如说是 10),如果能连通,那么就将服务器发送过去;如果无法连通 MX 记录为 10 的服务器,才将邮件发送到权重更高的 mail 服务器上。
多种类型的DNS记录共存关系图如下
| NS | CNAME | A | MX | |
|---|---|---|---|---|
| NS | 不限 | 不能共存 | 不能共存 | 不能共存 |
| CNAME | 不能共存 | 不能共存 | 不能共存 | 不能共存 |
| A | 不能共存 | 不能共存 | 不限 | 不限 |
| MX | 不能共存 | 不能共存 | 不限 | 不限 |
如下图所示,在已有A记录的情况下,添加NS记录,系统会进行报错。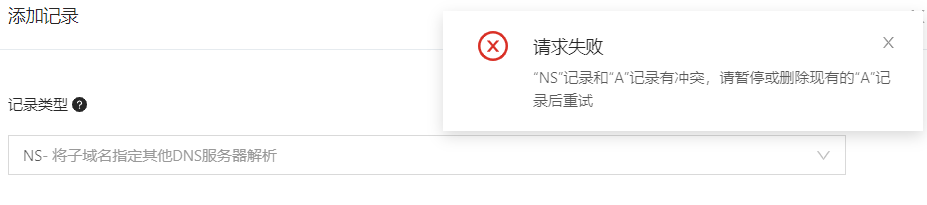
知道DNS解析记录的类型之后,我们来看一下怎么通过DNS解析来实现负载均衡
DNS负载均衡
负载均衡实现方式
通过A记录方式实现负载均衡
| 主机记录 | 记录类型 | 线路类型 | 记录值 | TTL |
|---|---|---|---|---|
| www | A | 默认 | 200.202.101.1 | 600 |
| www | A | 默认 | 200.202.101.2 | 600 |
| www | A | 默认 | 200.202.101.3 | 600 |
| www | A | 默认 | 200.202.101.4 | 600 |
同一个域名配置多个IP地址,解析返回得到的 IP 地址是轮询随机得到的 IP 地址,这样,本地DNS服务器会向客户端返回多个IP地址作为域名的查询结果,并且这些IP地址的排列顺序是轮换的。客户端一般会选择首个IP地址进行访问。
通过A记录方式实现负载均衡不会根据服务器负载和运行状况进行分配。
通过CNAME方式实现负载均衡
我们知道顶级域名有多个,当网站做大的时候,我们通常会把多个项级域名都买下来,指向同一个网站。比如
www.taobao.com
www.taobao.cn
www.taobao.org
都指向了淘宝网。而我们希望多对外域名统一作一个负载均衡。那么我们可以将多个域名指向同一个CNAME别名,再将CNAME别名指向多个A记录来进行负载均衡。
负载均衡器作为权威DNS服务器
我们可以建立DNS服务器,通过godaddy等平台将注册自己的DNS服务器,再将域名映射一个NS记录到自己的DNS服务器。这里,自己的DNS服务器将实现负载均衡功能。
负载均衡器作为代理DNS服务器
在这种方式下,负载均衡器被注册为一个域名空间的权威DNS服务器,而真正的权威域名服务器则部署在负载均衡器后面。所有的DNS请求都会先到达负载均衡器,由负载均衡器转发至真正的权威DNS服务器,然后修改权威DNS服务器返回的响应信息,从而实现负载均衡功能。
为实现这一过程,首先要将对外公布的权威DNS服务器的地址注册成负载均衡器上的VIP地址。真正的权威DNS服务器正常响应浏览器的DNS请求,返回域名解析结果列表,这个响应会先发送到负载均衡器,而负载均衡器会根据自己的策略选择一个性能最好的服务器IP并修改DNS服务器的应答信息,然后将应答信息转发给客户。负载均衡器只修改需要实现GSLB的域名的DNS查询响应,对其他请求透明转发,这样就不会影响整个域名空间的解析性能。
DNS负载均衡缺点
DNS负载均衡有一个很大的缺点就是延时性问题,在做出调度策略改变以后,由于DNS各级节点的缓存并不会及时的在客户端生效,而且DNS负载的调度策略比较简单,无法满足更复杂的业务需求。
CDN(内容分发网络)分流
抛却其他影响服务质量的因素,仅从网络传输的角度看,一个互联网系统的速度取决于以下四个因素。
- 网站服务器的出口带宽。
- 用户客户端的入口带宽。
- 从网站到用户经过的不同运营商之间的互联节点的带宽
- 从网站到用户的物理链路传输时延
除了第2用户的入口带宽是由用户换一个更好的宽带才能改善之外,其余三个,我们可以通过构建一个离用户近的,带宽大的服务来实现。这个离用户近、带宽大的服务就是CDN。
CDN的工作流程为: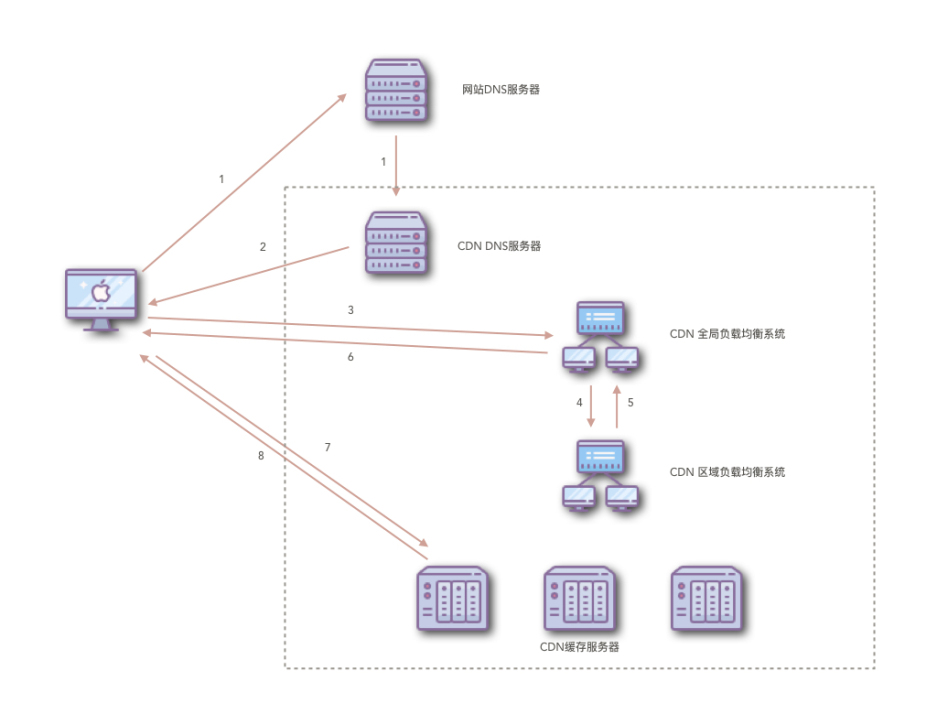
- 当用户点击网站页面上的内容URL,经过本地DNS系统解析,DNS系统会最终将域名的解析权交给CNAME指向的CDN专用DNS服务器。
- CDN的DNS服务器将CDN的全局负载均衡设备IP地址返回用户。
- 用户向CDN的全局负载均衡设备发起内容URL访问请求。
- CDN全局负载均衡设备根据用户IP地址,以及用户请求的内容URL,选择一台用户所属区域的区域负载均衡设备,告诉用户向这台设备发起请求。
- 区域负载均衡设备会为用户选择一台合适的缓存服务器提供服务,选择的依据包括:根据用户IP地址,判断哪一台服务器距用户最近;根据用户所请求的URL中携带的内容名称,判断哪一台服务器上有用户所需内容;查询各个服务器当前的负载情况,判断哪一台服务器尚有服务能力。基于以上这些条件的综合分析之后,区域负载均衡设备会向全局负载均衡设备返回一台缓存服务器的IP地址。
- 全局负载均衡设备把服务器的IP地址返回给用户。
- 用户向缓存服务器发起请求,缓存服务器响应用户请求,将用户所需内容传送到用户终端。如果这台缓存服务器上并没有用户想要的内容,而区域均衡设备依然将它分配给了用户,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器将内容拉到本地。
客户端缓存
当我们通过dns解析或者cdn解析拿到内容时,如果内容没变化,那么我们希望客户端能尽量的把数据缓存起来。客户端属于最边缘的计算载体,客户端缓存一是加快获取数据的速度,二是减轻CDN与服务器的压力。我们知道,缓存是否能够应用的好,就看缓存有什么样的刷新策略。根据不同的缓存策略,Http缓存可以分为以下几种。状态缓存
状态缓存是指不经过服务器,客户端直接根据缓存信息对目标网站的状态判断,以前只有301/Moved Permanently(永久重定向)这一种;后来在RFC6797中增加了HSTS(HTTP Strict Transport Security)机制,用于避免依赖301/302跳转HTTPS时可能产生的降级中间人劫持,这也属于另一种状态缓存。强制缓存
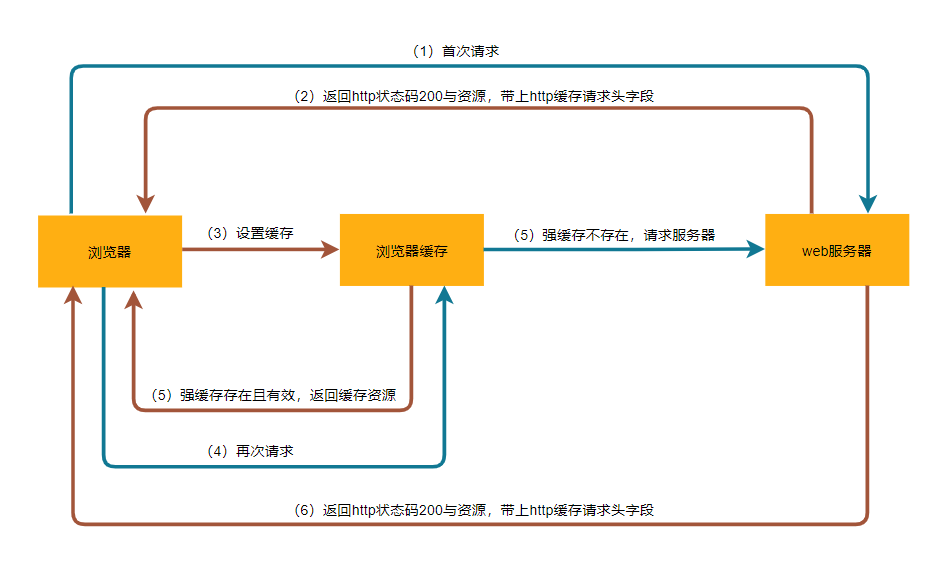
Expires:http response的响应时间。
Cache-control:控制浏览器中页面缓存状态。
Last-Modified:浏览器最后一次请求服务端资源修改的日期。协商缓存

tag/If-None-Match:url实体标签,类似于token,如果没有修改就返回状态码304,不会发送资源。
If-Modified-Since:再次请求服务端资源修改的日期,如果没有修改就返回状态码304,不会发送资源。
Cache-control设置了max-age与s-maxage值的话,Expires会被忽略,为了保证客户端能够获取到最新资源,建议都定义以上字段。
负载均衡
硬件负载均衡
硬件负载均衡是通过专门的硬件设备从而来实现负载均衡功能,比如:交换机、路由器就是一个负载均衡专用的网络设备。
目前典型的硬件负载均衡设备有两款:F5 和 A10。
硬件负载均衡的优点:
- 功能强大:支持各层级负载均衡及全面负载均衡算法;
- 性能强大:性能远超常见的软件负载均衡器;
- 稳定性高:硬件负载均衡,大规模使用肯定是严格测试过的;
- 安全防护:除具备负载均衡功能外,还具备防火墙、防 DDoS 攻击等安全功能;
硬件负载均衡的缺点:
- 价格昂贵;
- 可扩展性差;
- 调试维护麻烦;
软件负载均衡
负载均衡又分为四层负载均衡和七层负载均衡。四层负载均衡工作在OSI模型的传输层,主要工作是转发,它在接收到客户端的流量以后通过修改数据包的地址信息将流量转发到应用服务器。
七层负载均衡工作在OSI模型的应用层,因为它需要解析应用层流量,所以七层负载均衡在接到客户端的流量以后,还需要一个完整的TCP/IP协议栈。七层负载均衡会与客户端建立一条完整的连接并将应用层的请求流量解析出来,再按照调度算法选择一个应用服务器,并与应用服务器建立另外一条连接将请求发送过去,因此七层负载均衡的主要工作就是代理。四层负载均衡
四层负载均衡在接收到客户端的流量以后通过修改数据包的地址信息将流量转发到应用服务器。其中,我们可以修改IP地址,也可以修改MAC地址。四层负载均衡的优点是不对数据进行完全解析,不跟客户端建立连接(握手),请求分发的效率快。缺点是不支持更为灵活的负载均衡方式,比如基于url、session、动静分离等。
目前主要有四层转发模式:DR模式、NAT模式、TUNNEL模式、FULLNAT模式。实现模式
DR模式
DR(Direct Routing, 直接路由模式),也叫作三角传输,过修改数据包的目的MAC地址来让流量经过二层转发到达应用服务器,这样应用服务器就可以直接将应答发给应用服务器,性能比较好。作法为负载均衡服务器修改请求数据包的目标MAC地址,并且在Real Service服务配置只有自己可见的lo:VIP,实现数据包的接收(自己没有VIP的话,服务并不会接收数据包)。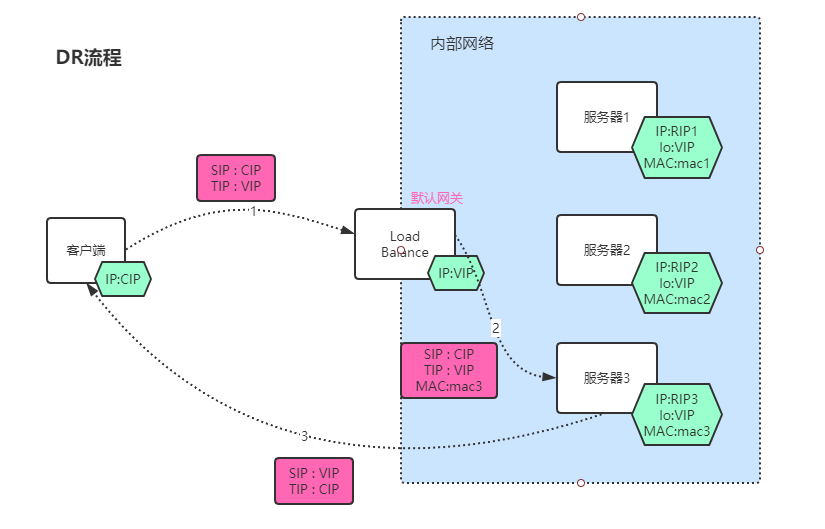
整个转发的流程为:
- 客户端发送请求,源IP:CIP,目标IP:VIP
- LB接收到请求,将数据帧中的目标MAC地址修改为Real Service的MAC 地址,通过调度算法选择转发到那台Real Service。
- Real Service 接收到请求,发现自己有VIP,端口号也匹配。于是接收数据,进行业务处理。并用VIP为IP地址,将响应数据直接发送给客户端。
DR模式下,LB只接收请求进行转发,响应数据有Real Service直接发送给客户端,降低了LB的压力。但是NAT和DR都需要LB和Real Service处于同一网段,无法将RS部署在不同的机房。
NAT模式
NAT(Network Address Translation,网络地址转换)模式通过修改数据包的目的IP地址,让流量到达应用服务器,这样做的好处是数据包的目的IP就是应用服务器的IP,因此不需要再在应用服务器上配置VIP了。缺点是由于这种模式修改了目的IP地址,这样如果应用服务器直接将应答包发给客户端的话,其源IP是应用服务器的IP,客户端就不会正常接收这个应答,因此我们需要让流量继续回到负载均衡,负载均衡将应答包的源IP改回VIP再发到客户端,这样才可以保证正常通信,所以NAT模式要求负载均衡需要以网关的形式存在于网络中。
作法为在专用内部网络中,分配一台实现了NAT技术的路由或服务Load Balance Service。这台负载均衡服务器分配了公网IP(VIP, Virtual IP),所有客户端请求服务都请求此IP。LBS通过不同的算法,将请求数据包的源IP以及目标IP修改,转发到真实服务器(Real Service)上进行业务处理。其具体的步骤可以分为: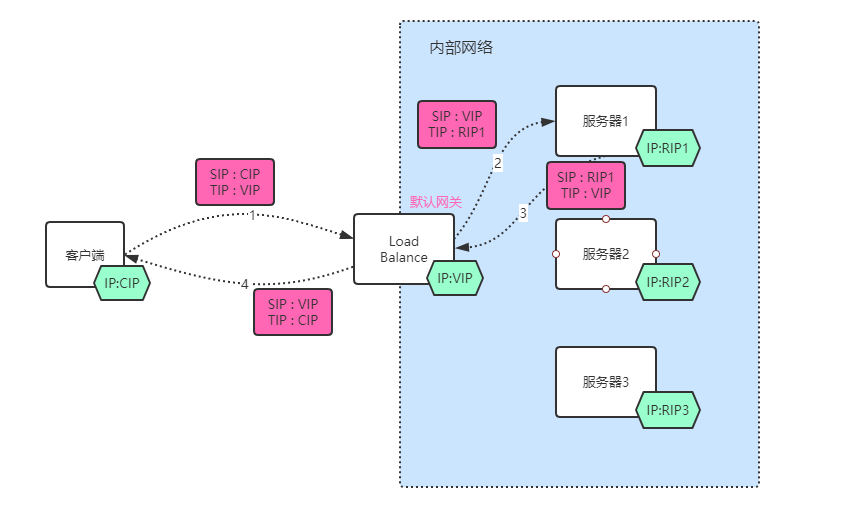
1、客户端发送请求,源IP为:CIP,目标IP为:VIP
2、LBS接收请求,解析数据报IP地址,将源IP修改为:VIP,目录IP修改为:RIP。具体修改为那个目标IP,通过算法的不同进行不同的选择。并将相关信息进行存储(MAP)后发送数据包。
3、RS 接收到请求,进行业务处理。并将结果返回给LBS。
4、LBS收到相应数据包,根据之前存储的MAP,将对应的SIP改为:VIP,TIP改为:CIP,将数据包发送出去。
注意:连接是建立在 客户端 与 Real Service 之间,LBS只是解析数据包IP和端口号,进行修改转发而已。
__可以看到通过NAT模式进行负载均衡,所有的请求以及响应都要通过LB服务器,当访问量较大时,LB服务器会成为瓶颈__。
TUNNEL模式
TUN思想跟DR类似,在Real Service上配置一个内部可见的lo:VIP地址,LB通过封装或修改数据包信息实现请求的转发。不同于DR模式LB修改MAC地址,为了实现不同网段的Real Service负载,TUN模式通过在原有的数据包外封装一层IP Tunnel ,实现数据的转发。由于封装完 IP Tunnel 后数据包和正常的数据包结构不同,所以Real Service的OS需要支持Tunnel功能。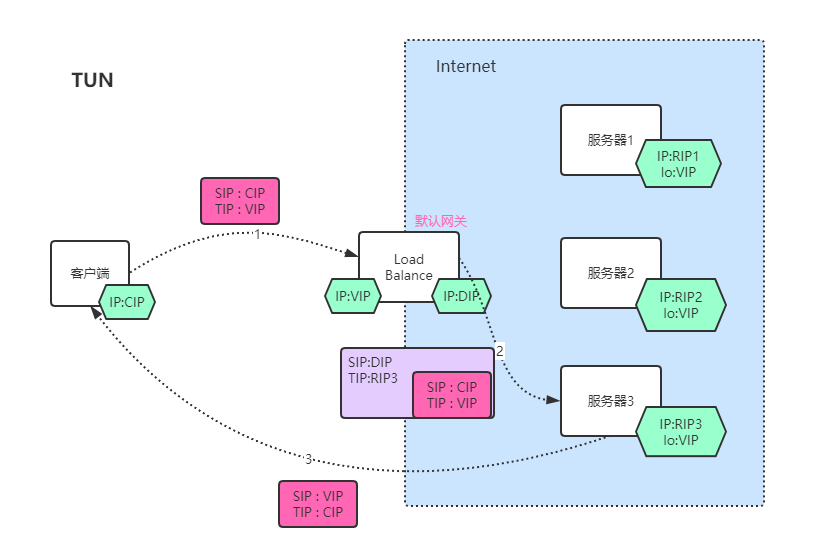
TUN转发的具体流程为:
- 客户端发送请求,SIP:CIP;TIP:VIP
- LB接收到请求,在数据包外在封装一层IP Tunnel,其SIP为DIP,TIP为RIP3.
- Real Service接收到请求,根据IP Tunnel 的IP地址判断出是发送给自己的请求,进行后续处理。根据源数据包的IP地址,判断出客户端的地址为CIP,并且VIP也是自己配置的IP,对数据进行业务处理后,通过VIP将响应数据直接发送到客户端。
实例
LVS
LVS是Linux Virtual Server的简称,也就是Linux虚拟服务器。它是一个由章文嵩博士发起的自由软件项目,官方站点是www.linuxvirtualserver.org。现在LVS已经是 Linux标准内核的一部分,在Linux2.4内核以前,使用LVS时必须要重新编译内核以支持LVS功能模块,但是从Linux2.4内核以后,已经完全内置了LVS的各个功能模块,无需给内核打任何补丁,可以直接使用LVS提供的各种功能。
LVS技术要达到的目标是:通过LVS提供的负载均衡技术和Linux操作系统实现一个高性能、高可用的服务器群集,它具有良好可靠性、可扩展性和可操作性。从而以低廉的成本实现最优的服务性能。
LVS自从1998年开始,发展到现在已经是一个比较成熟的技术项目了。可以利用LVS技术实现高可伸缩的、高可用的网络服务,例如WWW服务、Cache服务、DNS服务、FTP服务、MAIL服务、视频/音频点播服务等等,有许多比较著名网站和组织都在使用LVS架设的集群系统,例如:Linux的门户网站(www.linux.com)、向RealPlayer提供音频视频服务而闻名的Real公司(www.real.com)、全球最大的开源网站(sourceforge.net)等。
LVS目前有三种IP负载均衡技术(VS/NAT、VS/TUN和VS/DR);十种调度算法(rrr|wrr|lc|wlc|lblc|lblcr|dh|sh|sed|nq)七层负载均衡
通常使用的nginx负载均衡技术, 在网络分层中处于应用层(第七层)的,nginx与客户端建立TCP连接(握手),然后再根据请求信息以及本地配置信息,将请求灵活的分发到不同的服务上。nginx这类7层负载均衡的优缺点都很明显。
优点:可以将请求分发到不同的服务上,并且可以根据请求信息进行灵活的代理转发,实现更复杂的负载均衡控制,比如基于url、session、动静分离等;由于请求会通过负载均衡服务器,负载均衡服务器会过滤一些请求(例如:DOS攻击)避免所有请求信息都打到服务器上,保障了服务器的稳定运行。
缺点:处于网络分层的最上层,需要对数据进行解析,与客户端建立连接,效率比较低。
Nginx
Nginx是一款高性能的http 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。由俄罗斯的程序设计师Igor Sysoev所开发,官方测试nginx能够支支撑5万并发链接,并且cpu、内存等资源消耗却非常低,运行非常稳定。
nginx负载均衡的几种常用方式轮循
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
1
2
3
4upstream backserver {
server 192.168.0.3;
server 192.168.0.7;
}weight
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
1
2
3
4upstream backserver {
server 192.168.0.14 weight=3;
server 192.168.0.15 weight=7;
}ip_hash
在负载均衡系统中,假如用户在某台服务器上登录了,那么该用户第二次请求的时候,因为我们是负载均衡系统,每次请求都会重新定位到服务器集群中的某一个,那么已经登录某一个服务器的用户再重新定位到另一个服务器,其登录信息将会丢失,这样显然是不妥的。
我们可以采用ip_hash指令解决这个问题,如果客户已经访问了某个服务器,当用户再次访问时,会将该请求通过哈希算法,自动定位到该服务器。
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。1
2
3
4
5upstream backserver {
ip_hash;
server 192.168.0.14:88;
server 192.168.0.15:80;
}fair(三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
1
2
3
4
5upstream backserver {
server server1;
server server2;
fair;
}url_hash(三方)
按访问url的hash结果来分配请求,使每个url定向到同一个(对应的)后端服务器,后端服务器为缓存时比较有效。
1
2
3
4
5
6upstream backserver {
server squid1:3128;
server squid2:3128;
hash $request_uri;
hash_method crc32;
}在需要使用负载均衡的server中增加
1
2
3
4
5
6
7
8proxy_pass http://backserver/;
upstream backserver{
ip_hash;
server 127.0.0.1:9090 down; (down 表示单前的server暂时不参与负载)
server 127.0.0.1:8080 weight=2; (weight 默认为1.weight越大,负载的权重就越大)
server 127.0.0.1:6060;
server 127.0.0.1:7070 backup; (其它所有的非backup机器down或者忙的时候,请求backup机器)
}max_fails :允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream 模块定义的错误
fail_timeout:max_fails次失败后,暂停的时间
配置实例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29#user nobody;
worker_processes 4;
events {
# 最大并发数
worker_connections 1024;
}
http{
# 待选服务器列表
upstream myproject{
# ip_hash指令,将同一用户引入同一服务器。
ip_hash;
server 125.219.3.7 fail_timeout=60s;
server 172.31.3.7;
}
server{
# 监听端口
listen 80;
# 根目录下
location / {
# 选择哪个服务器列表
proxy_pass http://myproject;
}
}
}应用分流
当开发人员发现系统中某些资源的构建成本比较高,而这些资源又有被重复使用的可能时,会很自然地产生“循环再利用”的想法,将它们放到Map容器中,待下次需要时取出重用,避免重新构建,这种原始朴素的复用就是最基本的缓存。在应用中使用缓存,可以从缓存中取得数据,返回结果。
缓存
分布式缓存
Memcache
Memcached 是一个开源的、高性能的分布式 key/value 内存缓存系统。它以 key/value 键值对的方式存储数据,是一个键值类型的 NoSQL 组件。
Memcached 简称 Mc,是一个典型的内存型缓存组件,这就意味着,Mc 一旦重启就会丢失所有的数据。如下图所示,Mc 组件之间相互不通信,完全由 client 对 key 进行 Hash 后分布和协同。Mc 采用多线程处理请求,由一个主线程和任意多个工作线程协作,从而充分利用多核,提升 IO 效率。
Mc 的特性。Mc 最大的特性是高性能,单节点压测性能能达到百万级的 QPS。
其次因为 Mc 的访问协议很简单,只有 get/set/cas/touch/gat/stats 等有限的几个命令。Mc 的访问协议简单,跟它的存储结构也有关系。
Mc 存储结构很简单,只存储简单的 key/value 键值对,而且对 value 直接以二进制方式存储,不识别内部存储结构,所以有限几个指令就可以满足操作需要。
Mc 完全基于内存操作,在系统运行期间,在有新 key 写进来时,如果没有空闲内存分配,就会对最不活跃的 key 进行 eviction 剔除操作。
最后,Mc 服务节点运行也特别简单,不同 Mc 节点之间互不通信,由 client 自行负责管理数据分布。
Redis
Redis 是一款基于 ANSI C 语言编写的,BSD 许可的,日志型 key-value 存储组件,它的所有数据结构都存在内存中,可以用作缓存、数据库和消息中间件。
Redis 是 Remote dictionary server 即远程字典服务的缩写,一个 Redis 实例可以有多个存储数据的字典,客户端可以通过 select 来选择字典即 DB 进行数据存储。
同为 key-value 存储组件,Memcached 只能支持二进制字节块这一种数据类型。而 Redis 的数据类型却丰富的多,它具有 8 种核心数据类型,每种数据类型都有一系列操作指令对应。Redis 性能很高,单线程压测可以达到 10~11w 的 QPS。
虽然 Redis 所有数据的读写操作,都在内存中进行,但也可以将所有数据进行落盘做持久化。Redis 提供了 2 种持久化方式。快照方式,将某时刻所有数据都写入硬盘的 RDB 文件;
追加文件方式,即将所有写命令都以追加的方式写入硬盘的 AOF 文件中。
线上 Redis 一般会同时使用两种方式,通过开启 appendonly 及关联配置项,将写命令及时追加到 AOF 文件,同时在每日流量低峰时,通过 bgsave 保存当时所有内存数据快照。
本地缓存
本地缓存和应用同属于一个进程,使用不当会影响服务稳定性,所以通常需要考虑更多的因素,例如容量限制、过期策略、淘汰策略、自动刷新等。常用的本地缓存方案有:
- 根据HashMap自实现本地缓存
- Guava Cache
- Caffeine
- Encache
消息中间件
如果应用中的请求需要花费的时间比较长,或者一时间接收了大量的请求。我们可以使用消息中间件来进行分流。
当前业界比较流行的开源消息中间件包括:ActiveMQ、RabbitMQ、RocketMQ、Kafka、ZeroMQ等,其中应用最为广泛的要数RabbitMQ、RocketMQ、Kafka 这三款。Redis在某种程度上也可以是实现类似 “Queue” 和“ Pub/Sub” 的机制,严格意义上不算消息中间件。
数据库分流
单表容量
在中国互联网技术圈流传着这么一个说法:MySQL 单表数据量大于 2000 万行,性能会明显下降。再后来,阿里巴巴《Java 开发手册》提出单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。对此,有阿里的黄金铁律支撑,所以,很多人设计大数据存储时,多会以此为标准,进行分表操作。
我们知道,InnoDB存储引擎最小储存单元——页(Page),一个页的大小是16K。
这里我们先假设B+树高为2,即存在一个根节点和若干个叶子节点,那么这棵B+树的存放总记录数为:根节点指针数单个叶子节点记录行数。
假设一行记录的数据大小为1k,单个叶子节点(页)中的记录数=16K/1K=16。现在我们需要计算出非叶子节点能存放多少指针,其实这也很好算,我们假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节,我们一个页中能存放多少这样的单元,其实就代表有多少指针,即16384/14=1170。那么可以算出一棵高度为2的B+树,能存放117016=18720条这样的数据记录。
根据同样的原理我们可以算出一个高度为3的B+树可以存放:1170117016=21902400条这样的记录。所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。在查找数据时一次页的查找代表一次IO,所以通过主键索引查询通常只需要1-3次IO操作即可查找到数据。
对于使用InnoDB作为存储引擎的表来说,不管是用于存储用户数据的索引(包括聚簇索引和二级索引),还是各种系统数据,都是以页的形式存放在表空间中的,而所谓的表空间只不过是InnoDB对文件系统上一个或几个实际文件的抽象,也就是说我们的数据说到底还是存储在磁盘上的。但是各位也都知道,磁盘的速度慢的可以,所以InnoDB存储引擎在处理客户端的请求时,当需要访问某个页的数据时,就会把完整的页的数据全部加载到内存中,也就是说即使我们只需要访问一个页的一条记录,那也需要先把整个页的数据加载到内存中。将整个页加载到内存中后就可以进行读写访问了,在进行完读写访问之后并不着急把该页对应的内存空间释放掉,而是将其缓存起来,这样将来有请求再次访问该页面时,就可以省去磁盘IO的开销了。
设计InnoDB的大佬为了缓存磁盘中的页,在MySQL服务器启动的时候就向操作系统申请了一片连续的内存,他们给这片内存起了个名,叫做Buffer Pool(中文名是缓冲池)。那它有多大呢?这个其实看我们机器的配置,最小是5M,但如果你是土豪,你有512G内存,你分配个几百G作为Buffer Pool也可以的。
Buffer Pool是一个LRU缓存。从上图我们看到,如果表常用的话,数据在2千万以下,索引页还是很容易被缓存进目录的。所以查询的速度很快。但如果树高再增加一层,就需要21G的内存空间来进行索引,如果内存配置的够大的话,也是可以的。但如果再高一层,需要24T的内存来缓存索引,这个是土豪也不行的吧。
事实上,性能最快的肯定是数据都在内存里,2000万涉及到的是索引值是不是都能缓存进内存。而500万更多的是考虑到叶子节点缓存的占用。如果常用的叶子节点数据能够常驻在内存中,那数据应该查询的更快。分库分表策略
既然表的容量有限制,那么最好的办法就是分库分表。分库分表有水平与垂直两个策略来说。垂直分表就是按照业务,把一张表分成几个业务表,从而减少单表数量,每个表的字段不一样。水平分表就是把一张表的数据切成多份,存储在不同的表中,每个表的字段一样。水平分库分表策略
取模分片
错误做法:1
2
3
4
5
6
7
8public static ShardCfg shardByMod(Long userId) {
// 对库数量取余结果为库序号
int dbIdx = Math.abs(userId % DB_CNT);
// 对表数量取余结果为表序号
int tblIdx = Math.abs(userId % TBL_CNT);
return new ShardCfg(dbIdx, tblIdx);
}
其实稍微思索一下,我们就会发现,以 10 库 100 表为例,如果一个 值对 100 取余为 0,那么它对 10 取余也必然为 0。这就意味着只有 0 库里面的 0 表才可能有数据,而其他库中的 0 表永远为空!如果一个值对100取余为1,对10取余肯定也为1,那么1库1表才可会有数据。类似的我们还能推导到,0 库里面的共 100 张表,只有 10 张表中(个位数为 0 的表序号)才可能有数据。
这就带来了非常严重的数据偏斜问题,因为某些表中永远不可能有数据,最大数据偏斜率达到了无穷大。
事实上,只要库数量和表数量非互质关系,都会出现某些表中无数据的问题。
么是不是只要库数量和表数量互质就可用用这种分库分表方案呢?比如我用 11 库 100 表的方案,是不是就合理了呢?
答案是否定的,我们除了要考虑数据偏斜的问题,还需要考虑可持续性扩容的问题,一般这种 Hash 分库分表的方案后期的扩容方式都是通过翻倍扩容法,那 11 库翻倍后,和 100 又不再互质。
当然,如果分库数和分表数不仅互质,而且分表数为奇数(例如 10 库 101 表),则理论上可以使用该方案,但是我想大部分人可能都会觉得使用奇数的分表数比较奇怪吧。
正确做法:
一:
1 | |
将库与表取合标个序号,直接用序号取模。
二:
1 | |
优点
实现起来比较简单。
缺点
扩容数据需要迁移
不利于范围扫描查询操作
Range范围分库分表
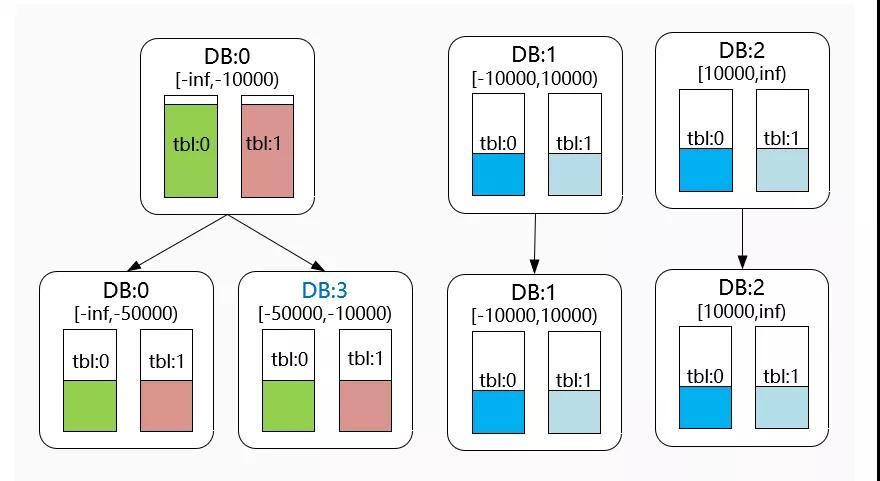
顾名思义,该方案根据数据范围划分数据的存放位置。
举个最简单例子,我们可以把订单表按照年份为单位,每年的数据存放在单独的库(或者表)中。
如下图所示:
1 | |
通过数据的范围进行分库分表,该方案是最朴实的一种分库方案,它也可以和其他分库分表方案灵活结合使用。
时下非常流行的分布式数据库:TiDB 数据库,针对 TiKV 中数据的打散,也是基于 Range 的方式进行,将不同范围内的[StartKey,EndKey)分配到不同的 Region 上。
优点
集群扩容后,指定新的范围落在新节点即可,无需进行数据迁移。
缺点
最明显的就是数据热点问题,例如上面案例中的订单表,很明显当前年度所在的库表属于热点数据,需要承载大部分的 IO 和计算资源。
新库和新表的追加问题。一般我们线上运行的应用程序是没有数据库的建库建表权限的,故我们需要提前将新的库表提前建立,防止线上故障。
这点非常容易被遗忘,尤其是稳定跑了几年没有迭代任务,或者人员又交替频繁的模块。
Hash分库分表
1
2
3
4
5
6
7
8
9public static ShardCfg shard(String userId) {
int hash = userId.hashCode();
// 对库数量取余结果为库序号
int dbIdx = Math.abs(hash / DB_CNT);
// 对表数量取余结果为表序号
int tblIdx = Math.abs(dbIdx % TBL_CNT);
return new ShardCfg(dbIdx, tblIdx);
}优点
实现起来比较简单。
缺点
扩容数据需要迁移
不利于范围扫描查询操作融合算法
这时我们应该意识到,以上介绍的哈希和范围的分片算法并不是非此即彼,二选一的。相反,我们可以灵活地组合它们。
例如,我们可以建立一个多级分片策略,该策略在最上层使用哈希算法,而在每个基于哈希的分片单元中,数据将按顺序存储。扩容方案
翻倍扩容法
具体的流程大致如下:
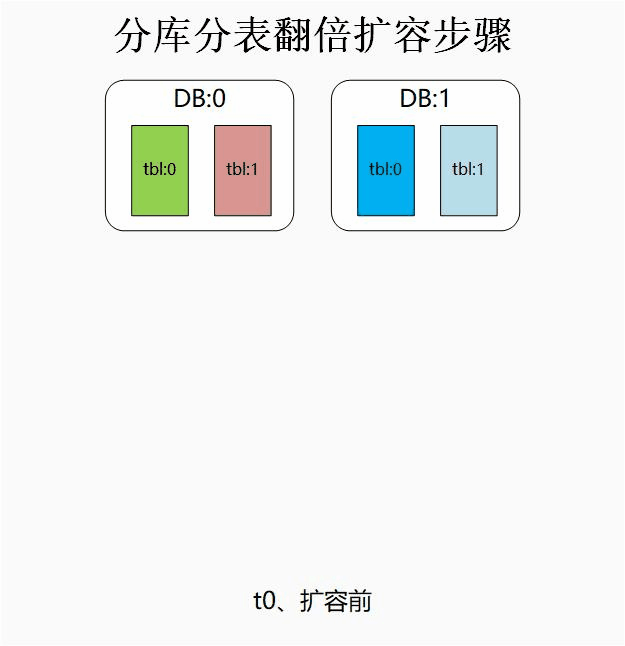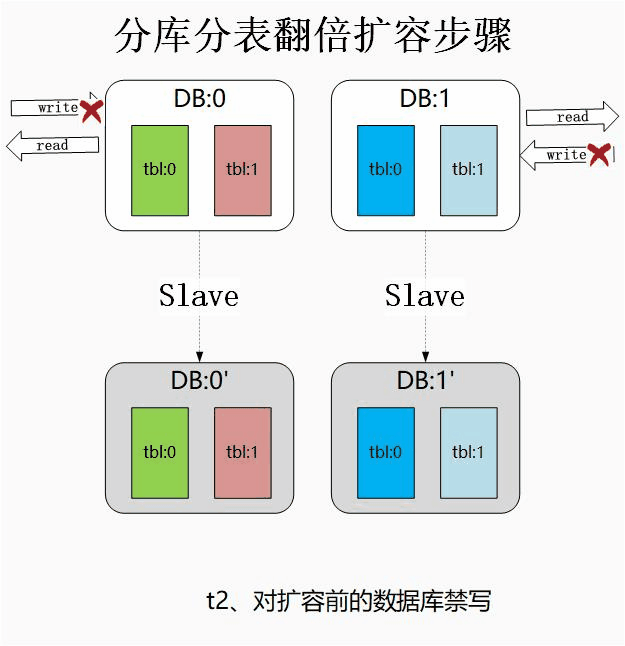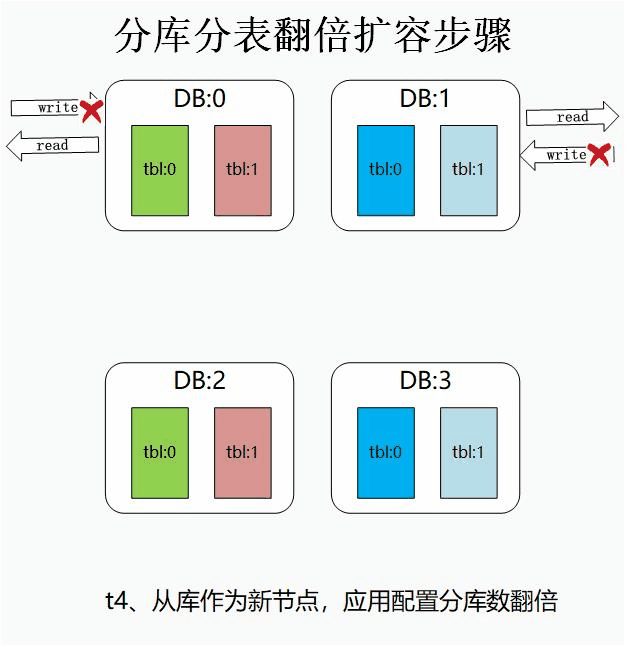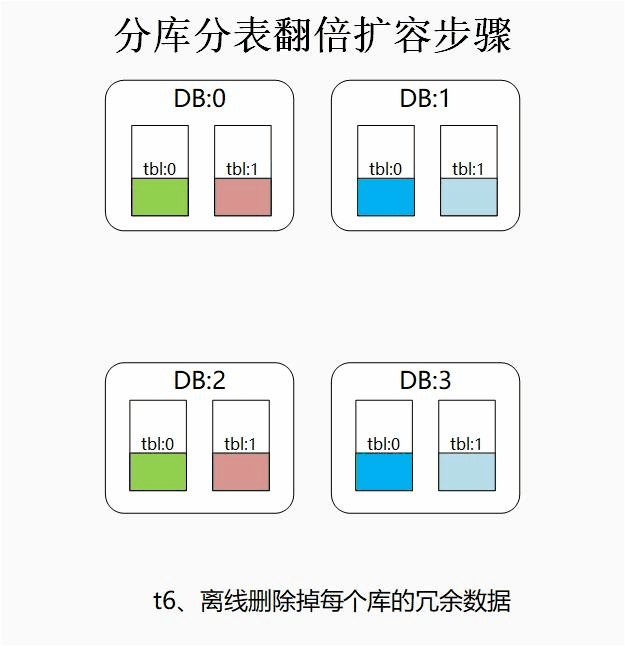
step1:为每个节点都新增从库,开启主从同步进行数据同步。
step2:主从同步完成后,对主库进行禁写。
此处禁写主要是为了保证数据的正确性。若不进行禁写操作,在以下两个时间窗口期内将出现数据不一致的问题:断开主从后,若主库不禁写,主库若还有数据写入,这部分数据将无法同步到从库中。
应用集群识别到分库数翻倍的时间点无法严格一致,在某个时间点可能两台应用使用不同的分库数,运算到不同的库序号,导致错误写入。
step3:同步完全完成后,断开主从关系,理论上此时从库和主库有着完全一样的数据集。
step4:从库升级为集群节点,业务应用识别到新的分库数后,将应用新的路由算法。
一般情况下,我们将分库数的配置放到配置中心中,当上述三个步骤完成后,我们修改分库数进行翻倍,应用生效后,应用服务将使用新的配置。
这里需要注意的是,业务应用接收到新的配置的时间点不一定一致,所以必定存在一个时间窗口期,该期间部分机器使用原分库数,部分节点使用新分库数。这也正是我们的禁写操作一定要在此步完成后才能放开的原因。
step5:确定所有的应用均接受到库总数的配置后,放开原主库的禁写操作,此时应用完全恢复服务。
启动离线的定时任务,清除各库中的约一半冗余数据。
为了节省磁盘的使用率,我们可以选择离线定时任务清除冗余的数据。也可以在业务初期表结构设计的时候,将索引键的 Hash 值存为一个字段。
一致性Hash扩容
一致性Hash算法
- 我们把节点通过hash后,映射到一个范围是[0,2^32]的环上
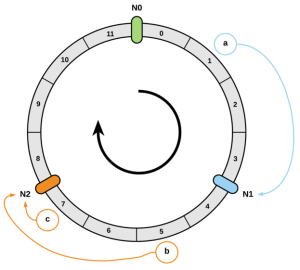
2.把数据也通过hash的方式映射到环上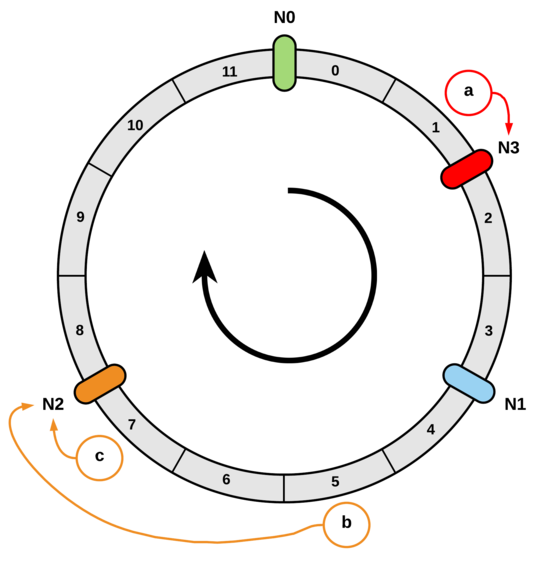
3.因为节点越多,它们在环上的分布就越均匀,使用虚拟节点还可以降低节点之间的负载差异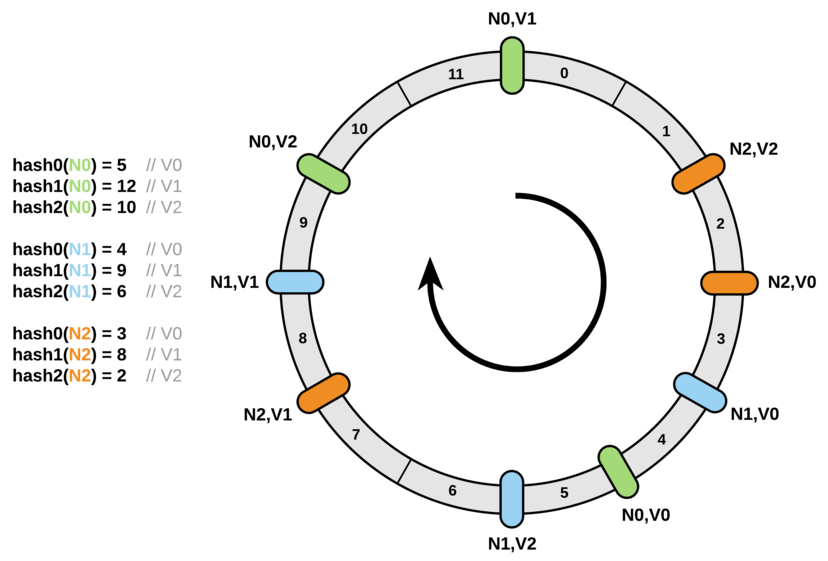
扩容
主要步骤如下:
- step1:针对需要扩容的数据库节点增加从节点,开启主从同步进行数据同步。
- step2:完成主从同步后,对原主库进行禁写。此处原因和翻倍扩容法类似,需要保证新的从库和原来主库中数据的一致性。
- step3:同步完全完成后,断开主从关系,理论上此时从库和主库有着完全一样的数据集。
- step4:修改一致性 Hash 范围的配置,并使应用服务重新读取并生效。
- step5:确定所有的应用均接受到新的一致性 Hash 范围配置后,放开原主库的禁写操作,此时应用完全恢复服务。
启动离线的定时任务,清除冗余数据。
可以看到,该方案和翻倍扩容法的方案比较类似,但是它更加灵活,可以根据当前集群每个节点的压力情况选择性扩容,而无需整个集群同时翻倍进行扩容。